What is BigQuery?
Google BigQuery is a fully-managed, serverless data warehouse that enables super-fast SQL queries using the processing power of Google’s infrastructure. It’s designed for analyzing large datasets and is commonly used for business intelligence, data analytics, and machine learning.BigQuery Connection Requirements
Unlike traditional databases that use username/password authentication, BigQuery uses Google Cloud Service Accounts for secure API access. This means you’ll need:- A Google Cloud Project with BigQuery enabled
- A Service Account with appropriate permissions
- A Service Account Key (JSON file) for authentication (how to generate)
- Below are the minimum required BigQuery permissions for Julius to work.
Providing the minimum required permissions
- Navigate to the Google Cloud Console IAM Roles
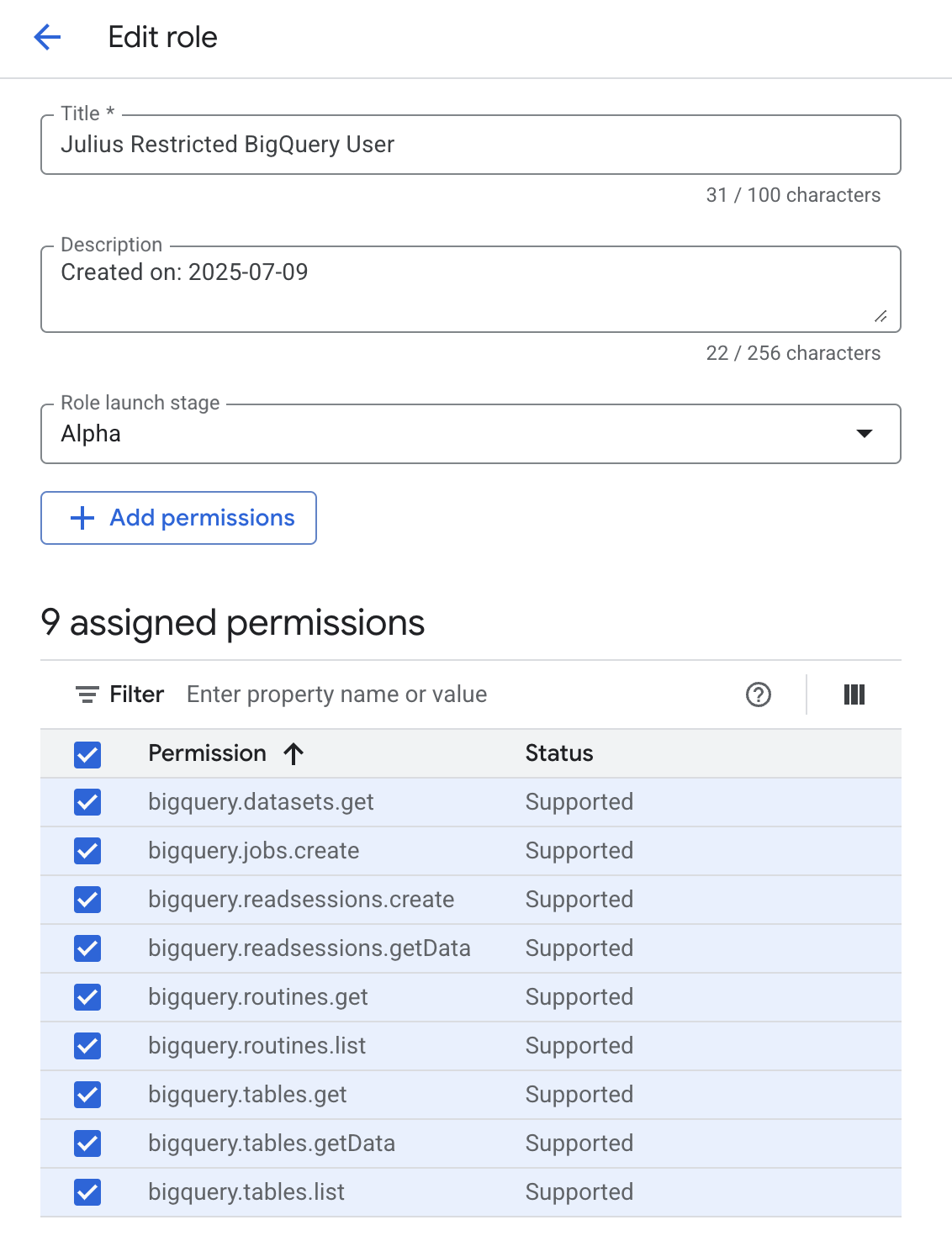
- Create a new role with the following permissions:
- Assign the roles to the service account
More Granular Permissions
The following permissions allow julius to access information about available tables. Currently, BigQuery does not provide a way to restrict viewing metadata to specific tables. However, you can restrict access to viewing the data within specific tables.bigquery.tables.get- Required to access metadata about a tablebigquery.tables.list- Required to list available tables in a datasetbigquery.routines.get- Required to access metadata about a routinebigquery.routines.list- Required to list available routines in a dataset
bigquery.tables.getData- Required to get data from a tablebigquery.readsessions.getData- Required to get data from a read session
Connecting Julius to BigQuery
Navigate to Data Connectors
- Go to your Julius Data Connectors Settings
- Click Create new Data Connector
- Select BigQuery from the available options
Configure Connection Details
You’ll see a form with the following fields:
Fields marked with an asterisk (*) are required to establish a connection.
- What it is: A friendly name to identify this BigQuery connection
- Example: “Production Analytics” or “Sales Data Warehouse”
- Tip: Choose a name that helps you remember which BigQuery project/datasets this connects to
- What it is: The complete JSON content from your downloaded service account key file
- How to use: Open the downloaded JSON file in a text editor and copy the entire contents
- Security: Julius encrypts and securely stores these credentials
- What it is: Multi-Factor Authentication type if your organization requires additional security
- When needed: Only if your Google Cloud organization has additional authentication requirements
- Most users: Can leave this blank unless specifically required by your organization’s security policy
Troubleshooting Common Issues
Authentication failed or invalid credentials
Authentication failed or invalid credentials
- Verify you copied the complete JSON content (including braces) - Check that the service account still exists in Google Cloud Console - Ensure the service account key hasn’t been deleted or disabled - Confirm the JSON format is valid (no extra characters or line breaks)
Permission denied errors
Permission denied errors
- Verify the service account has at minimum the
bigquery.jobs.create,bigquery.tables.get, andbigquery.tables.listpermissions - Check that the service account has BigQuery Job User and BigQuery Data Viewer roles - Check if datasets have additional access restrictions - Ensure BigQuery API is enabled in your Google Cloud project - Confirm you’re using the correct Google Cloud project
Julius can't find my tables or datasets
Julius can't find my tables or datasets
- Verify the service account has access to the specific datasets - Check dataset regions - ensure they’re in the same region or multi-region - Confirm table names and dataset IDs are correct - Ensure datasets aren’t deleted or moved to a different project
Reach out to [email protected] for support or to ask questions not answered in our documentation.